


HTTP/1.1 200 OK
Server: nginx/1.0.14
Date: Wed, 06 Jun 2012 08:21:29 GMT
Content-Type: video/x-msvideo
Connection: close
content-length: 82944
content-disposition: attachment; filename="clock.avi"
accept-ranges: bytes
etag: 47d
pragma: public
cache-control: max-age=0
петабайты информации на одном домене
Как хранятся файлы например в том же dropbox ? Все public ссылки ведут на dl.dropbox.com но файлы расположены ведь на разных серверах. nslookup показывает 8 ip адресов. Каким образом выбирается нужный файл из этих 8 серверов ? Если бы ссылки были вида dl1.dropbox.com dl2.dropbox.com ... dlN.dropbox.com то все ясно, а на одном домене как ?
Спасибо.
Спасибо.
1) ничто не мешает организовать такой один массив например из SAN/NAS.
2) ничто не мешает обрабатывать запросы сервером, который знает на каком серваке какие хранятся файлы. и при переходе по ссылке редиректить на нужный файл.
А то что выдал nslookup это лишь ip веб-серверов. Это не означает что у них всего 8 серваков.
2) ничто не мешает обрабатывать запросы сервером, который знает на каком серваке какие хранятся файлы. и при переходе по ссылке редиректить на нужный файл.
А то что выдал nslookup это лишь ip веб-серверов. Это не означает что у них всего 8 серваков.
Ну учитывая сколько пользователей в том же dropbox одного даже гигабитного канала явно не хватило бы, - объясню почему: редиректа у них нет, только что открыл firebug и посмотрел куда запрос пошел. Файл скачался с https://dl.dropbox.com/s/31nk1j3yic0n8gf/clock.avi?dl=1
А SAN/NAS имеет узкое место в виде небезлимитного канала.
Нет, все ничего когда пользователей до 100k, а если больше?
Я же говорю, если бы были ссылки вида dl1.dropbox, dl2.dropbox и т.д. все было бы ясно, а так? Чисто спортивный интерес.
Кстати, забыл сказать, dropbox основан на амазон s3 если кто не в курсе, и если это что-то меняет.
А SAN/NAS имеет узкое место в виде небезлимитного канала.
Нет, все ничего когда пользователей до 100k, а если больше?
Я же говорю, если бы были ссылки вида dl1.dropbox, dl2.dropbox и т.д. все было бы ясно, а так? Чисто спортивный интерес.
Кстати, забыл сказать, dropbox основан на амазон s3 если кто не в курсе, и если это что-то меняет.
:-}
пфф. ну что вы такое говорите?
Конкретно про амазон с3: файлы при алоаде туда автоматически дублируются на нескольких серверах. у них своя файловая система. днс записи обновляются/изменяются регулярно (балансировка нагрузки). сервис достаточно большой поетому использует магистральные каналы, а не "гигабитный интернет от укртелеком", так что со скоростью там все в порядке. файлы не хранятся физически в файловой системе - организация "физического" хранения данных у них немного иная.
Вы хотите услышать конкретный ответ? Или просто подискутировать? Или вам просто интересно?
Q: Как хранятся файлы например в том же dropbox ?
A: Файлы хранятся в облачном сервисе Amazon S3
Q: Все public ссылки ведут на dl.dropbox.com но файлы расположены ведь на разных серверах. nslookup показывает 8 ip адресов.
A:Это 8 веб-серверов которые обрабатывают http-запрос и отдают вам файл. сам файл не обязан храниться на этом же сервере.
Q: Каким образом выбирается нужный файл из этих 8 серверов ?
A:При обращении к любому ip вы получите этот файл. А вообще ОС пользователя выбирает случайно понравившуюся запись.
пфф. ну что вы такое говорите?
Конкретно про амазон с3: файлы при алоаде туда автоматически дублируются на нескольких серверах. у них своя файловая система. днс записи обновляются/изменяются регулярно (балансировка нагрузки). сервис достаточно большой поетому использует магистральные каналы, а не "гигабитный интернет от укртелеком", так что со скоростью там все в порядке. файлы не хранятся физически в файловой системе - организация "физического" хранения данных у них немного иная.
Вы хотите услышать конкретный ответ? Или просто подискутировать? Или вам просто интересно?
Q: Как хранятся файлы например в том же dropbox ?
A: Файлы хранятся в облачном сервисе Amazon S3
Q: Все public ссылки ведут на dl.dropbox.com но файлы расположены ведь на разных серверах. nslookup показывает 8 ip адресов.
A:Это 8 веб-серверов которые обрабатывают http-запрос и отдают вам файл. сам файл не обязан храниться на этом же сервере.
Q: Каким образом выбирается нужный файл из этих 8 серверов ?
A:При обращении к любому ip вы получите этот файл. А вообще ОС пользователя выбирает случайно понравившуюся запись.
Хочу подискутировать, ибо поговорить в жизни о таком мало с кем возможно + в интернете информация хоть и есть, но в общих чертах. Меня интересуют подробности.
Т.е. при обращении в dl.dropbox.com происходит round robin между 8 серверами, которые отдают статику, на каждом из них также хранится скрипт, который улавливает id файла, ищет в базе где он расположен физически и отдает файл через себя? Если так то получается что:
- Если отдавать через себя то скорость ограничивается скоростью порта одного сервера (Зачем из одного сервера лить в другой, потом оттуда забирать, если можно сразу отдать из того где физически расположен файл?) - Амазон не зря сделал так, они ж ведь умные люди. Так почему именно так? (Вероятней всего оно ж то не так, так что поправьте меня где я ошибся).
P.S. 1Гбит имелось ввиду для одного сервера, а не для системы в целом =))) Пока больше 1Гб не встречал просто.
Т.е. при обращении в dl.dropbox.com происходит round robin между 8 серверами, которые отдают статику, на каждом из них также хранится скрипт, который улавливает id файла, ищет в базе где он расположен физически и отдает файл через себя? Если так то получается что:
- Если отдавать через себя то скорость ограничивается скоростью порта одного сервера (Зачем из одного сервера лить в другой, потом оттуда забирать, если можно сразу отдать из того где физически расположен файл?) - Амазон не зря сделал так, они ж ведь умные люди. Так почему именно так? (Вероятней всего оно ж то не так, так что поправьте меня где я ошибся).
P.S. 1Гбит имелось ввиду для одного сервера, а не для системы в целом =))) Пока больше 1Гб не встречал просто.
Стоп-стоп... Кажется я начинаю понимать (если снова ничего не путаю). Т.е. заголовок (длина + имя файла) отдается из этих 8 серверов, а файл (сами данные напрямую из другого?)
Ну ладно, раз все так запутано давайте разберемся на примере одного простого файла:
https://dl.dropbox.com/s/31nk1j3yic0n8gf/clock.avi?dl=1
Видно что запрос пошел на https://dl.dropbox.com/s/31nk1j3yic0n8gf, выставил статус PENDING ... загрузил 286 байт (судя по всему заголовок), затем статус Canceled и непонятно откуда стал загружать файл. Хотя бы в коде или лучше на словах, уж как нибудь поясните эту систему )))
Ну ладно, раз все так запутано давайте разберемся на примере одного простого файла:
https://dl.dropbox.com/s/31nk1j3yic0n8gf/clock.avi?dl=1
Видно что запрос пошел на https://dl.dropbox.com/s/31nk1j3yic0n8gf, выставил статус PENDING ... загрузил 286 байт (судя по всему заголовок), затем статус Canceled и непонятно откуда стал загружать файл. Хотя бы в коде или лучше на словах, уж как нибудь поясните эту систему )))
Эти сервера так сказать "шлюзы" и "маршрутизаторы" трафика из датацентра конечному пользователю. Амазон С3 обрабатывает более 500 000 запросов / сек. несколькими датацентрами. Для каждого запроса нужно распарсить http-запрос, проверить валидность, проверить наличие файла, проверить чей это аккаунт и т.д. Кроме того сервера в фоне проверяют целостность данных, кешируют, распределяют нагрузку между собой и т.д. 1 сервер с такой нагрузкой не справится.
Сервера находятся в одном датацентре, соединены между собой по оптике, поэтому передать данные с одного сервера на другой - не проблема.
Вообще у Амазона на облако более 400 000 серверов идет. (У гугла по последним данным около 900 000 серверов)
тут можешь поискать более подробную инфу.
Ну и так - интересная инфа Amazon S3 генерирует более 1% мирового трафика интернета, Youtube - более 6% трафика.
Сервера находятся в одном датацентре, соединены между собой по оптике, поэтому передать данные с одного сервера на другой - не проблема.
Вообще у Амазона на облако более 400 000 серверов идет. (У гугла по последним данным около 900 000 серверов)
тут можешь поискать более подробную инфу.
Ну и так - интересная инфа Amazon S3 генерирует более 1% мирового трафика интернета, Youtube - более 6% трафика.
Цитата: ASoftware
Видно что запрос пошел на https://dl.dropbox.com/s/31nk1j3yic0n8gf, выставил статус PENDING ... загрузил 286 байт (судя по всему заголовок), затем статус Canceled и непонятно откуда стал загружать файл. Хотя бы в коде или лучше на словах, уж как нибудь поясните эту систему )))
чем смотрел?
1) PENDING - ожидание - состояние когда клиент послал запрос и ждет ответа с сервера.
2) ???
3) CANCELED - сервер передал ответ и закрыл соединение.
Цитата:
чем смотрел?
1) PENDING - ожидание - состояние когда клиент послал запрос и ждет ответа с сервера.
2) ???
3) CANCELED - сервер передал ответ и закрыл соединение.
1) PENDING - ожидание - состояние когда клиент послал запрос и ждет ответа с сервера.
2) ???
3) CANCELED - сервер передал ответ и закрыл соединение.
Вот именно , второй пункт - "???" ибо между pending и canceled происходит загрузка нескольких байтов ( судя по всему размер заголовка 298 байт)
Смотрел Developer Tools в Google chrome
Обычно когда скачиваю файл, видно прямую ссылку, и то как он загружается (полный размер)
Обычная загрузка - 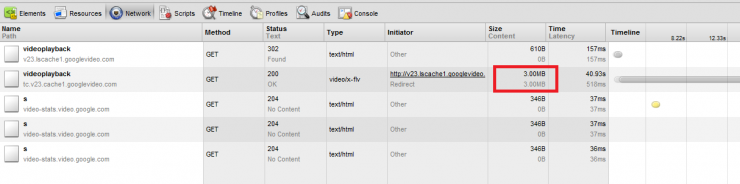
Как происходит в amazon - 
При чем файл понятно что скачивается нормально что так что так...
Цитата: ASoftware
Цитата:
чем смотрел?
1) PENDING - ожидание - состояние когда клиент послал запрос и ждет ответа с сервера.
2) ???
3) CANCELED - сервер передал ответ и закрыл соединение.
1) PENDING - ожидание - состояние когда клиент послал запрос и ждет ответа с сервера.
2) ???
3) CANCELED - сервер передал ответ и закрыл соединение.
Вот именно , второй пункт - "???" ибо между pending и canceled происходит загрузка нескольких байтов ( судя по всему размер заголовка 298 байт)
Смотрел Developer Tools в Google chrome
Обычно когда скачиваю файл, видно прямую ссылку, и то как он загружается (полный размер)
Обычная загрузка -
Как происходит в amazon -
При чем файл понятно что скачивается нормально что так что так...
Может быть лучше WireShark'ом посмотреть(записать сессию и проанализировать), чтоб не было вот этого:
2) ???
?
Цитата: ASoftware
Цитата:
чем смотрел?
1) PENDING - ожидание - состояние когда клиент послал запрос и ждет ответа с сервера.
2) ???
3) CANCELED - сервер передал ответ и закрыл соединение.
1) PENDING - ожидание - состояние когда клиент послал запрос и ждет ответа с сервера.
2) ???
3) CANCELED - сервер передал ответ и закрыл соединение.
Вот именно , второй пункт - "???" ибо между pending и canceled происходит загрузка нескольких байтов ( судя по всему размер заголовка 298 байт)
Смотрел Developer Tools в Google chrome
Обычно когда скачиваю файл, видно прямую ссылку, и то как он загружается (полный размер)
Обычная загрузка -
Как происходит в amazon -
При чем файл понятно что скачивается нормально что так что так...
Ну хз, у меня 200 OK пришло. Посмотри заголовки.
Я вам уже наверное изрядно поднадоел, но все таки не отстану, уж извиняйте :)
У меня также пришло 200 OK, вот весь заголовок:
Request URL:https://dl.dropbox.com/s/31nk1j3yic0n8gf/clock.avi?dl=1
Request Method:GET
Status Code:200 OK
Connection:keep-alive
Content-Type:video/x-msvideo
Date:Wed, 06 Jun 2012 07:42:04 GMT
Server:nginx/1.0.14
accept-ranges:bytes
cache-control:max-age=0
content-disposition:attachment; filename="clock.avi"
content-length:82944
etag:47d
pragma:public
Или просто header ("Location: http://data5.site.com/?id=binarydata"); ?
У меня также пришло 200 OK, вот весь заголовок:
Цитата:
Request URL:https://dl.dropbox.com/s/31nk1j3yic0n8gf/clock.avi?dl=1
Request Method:GET
Status Code:200 OK
Connection:keep-alive
Content-Type:video/x-msvideo
Date:Wed, 06 Jun 2012 07:42:04 GMT
Server:nginx/1.0.14
accept-ranges:bytes
cache-control:max-age=0
content-disposition:attachment; filename="clock.avi"
content-length:82944
etag:47d
pragma:public
Только тут отличие, когда файл скачивается например с обычного файлообменника, отображается полный размер и видно что качается 3,5, 10 Мб. А тут закачалось каких-то 292 байта, хотя скачиваемый файл намного больше.
Может быть сервер не пропускает через себя файл, а только отдает заголовок (длину + имя) а дальше переадресовывает на чистые данные совершенно на другой сервер, и получается что эти 8 серверов (пусть к примеру с Гб каналом каждый) отдают только заголовок и ищут файл в общей базе, тогда еще можно поверить что 8 серверов выдерживают нагрузку на весь амазон с3 (имеется ввиду выдерживают потребность в отдаче ТОЛЬКО заголовков), но врядли они пропускают через себя файлы.
Хотя я повторюсь, что это мои догадки, возможно все не так. Да, то что у них оптика, для каждого запроса нужно распарсить http-запрос, проверить валидность, проверить наличие файла, проверить чей это аккаунт и т.д. это все понятно.
А как можно к примеру в скрипте это сделать, т.е. типа
Код:
<?php
header ("HTTP/1.1 200 OK");
header ("Content-Type: video/x-flv");
header ("content-length: 6420826");
header ("accept-ranges: bytes");
И вот тут как-то перенаправить на другой сервер с чистыми двоичными данными.
Как это возможно сделать???
Просто echo 'http://data.site.com/data.php?id=someID'; нельзя, он же так будет пропускать его через себя
?>
header ("HTTP/1.1 200 OK");
header ("Content-Type: video/x-flv");
header ("content-length: 6420826");
header ("accept-ranges: bytes");
И вот тут как-то перенаправить на другой сервер с чистыми двоичными данными.
Как это возможно сделать???
Просто echo 'http://data.site.com/data.php?id=someID'; нельзя, он же так будет пропускать его через себя
?>
Цитата: ASoftware
А как можно к примеру в скрипте это сделать, т.е. типа
Код:
<?php
header ("HTTP/1.1 200 OK");
header ("Content-Type: video/x-flv");
header ("content-length: 6420826");
header ("accept-ranges: bytes");
И вот тут как-то перенаправить на другой сервер с чистыми двоичными данными.
Как это возможно сделать???
Просто echo 'http://data.site.com/data.php?id=someID'; нельзя, он же так будет пропускать его через себя
?>
header ("HTTP/1.1 200 OK");
header ("Content-Type: video/x-flv");
header ("content-length: 6420826");
header ("accept-ranges: bytes");
И вот тут как-то перенаправить на другой сервер с чистыми двоичными данными.
Как это возможно сделать???
Просто echo 'http://data.site.com/data.php?id=someID'; нельзя, он же так будет пропускать его через себя
?>
Цитата: arrjj
Прочитай мой предыдущий пост
Хз, у меня все показывает нормально. Мб в хроме с https беда? Или чтото из хидеров неправильно определяет (content-disposition наверно - устрой эксперимент)
Код:
Цитата:
Прочитай мой предыдущий пост
Заголовки теже, не в этом суть. Суть в том что загрузка происходит так как будто файл загружается из одного из этих 8 серверов. Ну не могу поверить я в то что файлы льются через них, пусть их и 8, и пусть даже каналы у них по 100Гбит в каждом.
Я же говорю, верю в теорию что эти 8 отдают только заголовки, а сам файл из другого сервера. Как программно это реализовать ? Не редиректом. Такое вообще возможно?
Цитата: ASoftware
Цитата:
Прочитай мой предыдущий пост
Заголовки теже, не в этом суть.
ты не тот пост прочитал. прочитай про over 9000 серверов у амазона.
Цитата: ASoftware
Я же говорю, верю в теорию что эти 8 отдают только заголовки, а сам файл из другого сервера. Как программно это реализовать ? Не редиректом. Такое вообще возможно?
Способов много. Например както так извратится можно.
Но я уверен почему то что они пользуются такой штукой, причем самостоятельно допиленой до нужной кондиции.
погугли фотки чтоб явно представить что для организации работы предприятия такого масштаба требуется чуть больше чем 8 серверов.
спасибо тему можно закрыть