

--------------------------------------------------------------------------------
Размер Описание
--------------------------------------------------------------------------------
3 байта Имя поля (ASCIIz)
2 байта Размер поля
2 байта Тип счетчика (ниже объясню)
2 байта ???
2 байта ???
2 байта Тип поля. Тут такая штука: типы заданы кодом. Вот некоторые, которые понял:
0x0a: беззнаковый символьный (unsigned char)
0x012: знаковый символьный (char)
0x14 и 0x16: знаковый целочисленный (int)
0x22: символьная строка, указанной длины (char[...])
Соответственно, длина указана в "Размере поля"
формат БД
Добрый день.
У меня вопрос. Есть файловая БД.
Надо найти чем её можно открыть. И еще лучше чем к ней подключится.
файлик/и могу выслать на мыло. Тут ругается что много весят :(
Пробывал что то получить от winhex но увидел только начало - 43 4D 4D 49
Подскажите откуда начинать и куда капать.
У меня вопрос. Есть файловая БД.
Надо найти чем её можно открыть. И еще лучше чем к ней подключится.
файлик/и могу выслать на мыло. Тут ругается что много весят :(
Пробывал что то получить от winhex но увидел только начало - 43 4D 4D 49
Подскажите откуда начинать и куда капать.
Цитата: Sandulf
А никто не пробовал вместо разбора постоянно меняющегося формата БД разобраться с функциями LexDdm.dll в ETKA? Это ж по сути набор функций для работы с данной БД.
это если подключаться к ЕТКА то можно, а если нужно сливать в MySQL (т.е. максимально точно знать формат полей в таблице) - то все равно отслеживать придется
В списке запчастей выбранной подгруппы в поле "ВВОД ДАННЫХ ПО МОДЕЛИ" можно также встретить PR-номера. Они встречаются в разных форматах со специальными символами внутри , например
Расшифровывать следует вот так
PR-N7U/N7V - любой из этих номеров должен присутствовать в расшифровке вина (они одной "фэмили" - SIB-Обивка сидений, т.е взаимоисключающие)
N7U SIB Обивка сиденья Alcantara и Perlnappa Обивка сидений
N7V SIB Обивка сиденья из драпировочной массы иPerlnappa Обивка сидений
PR-Q1A,N3Q - оба кода должны присутствовать (они с разных фэмили)
N3Q SIB Обивка сидений: кожа "Feinnappa" Обивка сидений
Q1A VOS Стандартные передние сиденья Передние сиденья
PR-0GV+ARX - "0GV" - Евро 2, ARX это уже код коробки или двигателя (не PR!)
N7U SIB Обивка сиденья Alcantara и Perlnappa Обивка сидений
N7V SIB Обивка сиденья из драпировочной массы иPerlnappa Обивка сидений
PR-Q1A,N3Q - оба кода должны присутствовать (они с разных фэмили)
N3Q SIB Обивка сидений: кожа "Feinnappa" Обивка сидений
Q1A VOS Стандартные передние сиденья Передние сиденья
PR-0GV+ARX - "0GV" - Евро 2, ARX это уже код коробки или двигателя (не PR!)
соответственно "+" это просто перечисление/разделение условий, т.е там human readable строка вида
"двигатель А + PR-коды XX1 или XX2 и ZZZ + коробка Б или С"
оболочка естественно для фильтрации использует не эту строку, у нее данные в нормальном виде есть )
Страницы V -> СИМВОЛЫ Полное описание использования сочетаний кодов и спец символов.
Подбор запчасти к VIN
отдельно по очереди проверяются дата, двигатель, коробка, пр-коды,коды стран, цвета и другое
"ВВОД ДАННЫХ ПО МОДЕЛИ" тоже участвует в фильтрации, но только строки вида F[D|M...] XXXX >> YYYYY
то есть "интервалы" дат, винов, серийников двигетеля и тд...
такие строки имеют определенный формат, нередко они кривые в данных
...еще учитывается "применимость верхнего уровня", то есть если "группа" по фильтру не подходит то автоматом не подходят и все детали,
хотя отдельно некоторые/все детали могут по фильтрам подходить...
отдельно по очереди проверяются дата, двигатель, коробка, пр-коды,коды стран, цвета и другое
"ВВОД ДАННЫХ ПО МОДЕЛИ" тоже участвует в фильтрации, но только строки вида F[D|M...] XXXX >> YYYYY
то есть "интервалы" дат, винов, серийников двигетеля и тд...
такие строки имеют определенный формат, нередко они кривые в данных
...еще учитывается "применимость верхнего уровня", то есть если "группа" по фильтру не подходит то автоматом не подходят и все детали,
хотя отдельно некоторые/все детали могут по фильтрам подходить...
Здравствуйте уважаемые!
Не судите строго, возможно пишу не в той теме, но вижу, что здесь есть люди, которые работают или понимают принципы ADABAS + Natural.
Сложилось так, что мне приходится работать с системой, которая писалась лет 10-15 назад.
Если коротко то: есть Server Linux Suse Enterprise 10 на котором крутится ADABAS. Есть много программ и подпрограмм написанных в Natural.
Доступ к данным осуществляется через браузер по http.
Чтобы лучше понять - прикрепил схему работы ...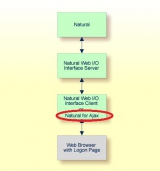
В этом направлении я полный новичок, поэтому извините за примитивные вопросы.
Вопросы:
1. Где точка входа (файл с которого начинается работа) всех этих подпрограмм?
2 .Как делать изменения в этих программах (подпрограммах)?
Я поставил Natural на Windows по удаленке подключаюсь на сервер, открываю нужную программу, делаю изменения на после перезапуска программы ничего не меняется - вроде ничего
и не менял (пробовал даже просто изменить заголовки полей) - ничего.
3. Есть необходимость экспорта данных из БД в .txt or .dbf. Для этого делаю бэкап БД на сервере -> разворачиваю его на локалке в себя,
а дальше ... (как я понимаю нужно создать для каждой таблицы (файла) БД DDM объект и с него уже выбирать данные?)
Так вот как это сделать? если можно детально ..
Не судите строго, возможно пишу не в той теме, но вижу, что здесь есть люди, которые работают или понимают принципы ADABAS + Natural.
Сложилось так, что мне приходится работать с системой, которая писалась лет 10-15 назад.
Если коротко то: есть Server Linux Suse Enterprise 10 на котором крутится ADABAS. Есть много программ и подпрограмм написанных в Natural.
Доступ к данным осуществляется через браузер по http.
Чтобы лучше понять - прикрепил схему работы ...
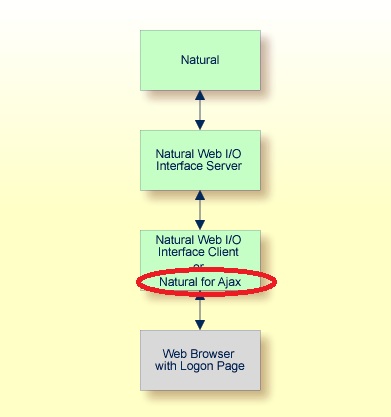
В этом направлении я полный новичок, поэтому извините за примитивные вопросы.
Вопросы:
1. Где точка входа (файл с которого начинается работа) всех этих подпрограмм?
2 .Как делать изменения в этих программах (подпрограммах)?
Я поставил Natural на Windows по удаленке подключаюсь на сервер, открываю нужную программу, делаю изменения на после перезапуска программы ничего не меняется - вроде ничего
и не менял (пробовал даже просто изменить заголовки полей) - ничего.
3. Есть необходимость экспорта данных из БД в .txt or .dbf. Для этого делаю бэкап БД на сервере -> разворачиваю его на локалке в себя,
а дальше ... (как я понимаю нужно создать для каждой таблицы (файла) БД DDM объект и с него уже выбирать данные?)
Так вот как это сделать? если можно детально ..
Цитата: Lerkin
1. Читаем 2 байта размера записи (26 00): длина записи - 38 байт
2. Читаем байт размера битовой маски полей (01): длина маски - 1 байт
3. Читаем этот один байт маски (90): в двоичном коде - 10010000.
...
Отсюда видно, что в данной записи присутствуют поля только TS и Text.
4. Поле TS имеет тип D (очевидно целочисленная 32-х битовая). Читаем 02 00 00 00 (число - 2, наверное просто номер строки)
5. Поле Text имеет тип S (очевидно строка переменной длины). Поэтому читаем байт размера длины строки 01: - размер длины строки - 1 байт.
6. Читаем этот один байт 1E: длина строки - 30 байт.
7. Читаем 30 байт поля Text. Получаем строку: ==============================
8. Чтение записи завершено. Повторить с начала всех для последующих строк :)
С другими типами полей и методами их чтения - экспериментируем.
2. Читаем байт размера битовой маски полей (01): длина маски - 1 байт
3. Читаем этот один байт маски (90): в двоичном коде - 10010000.
...
Отсюда видно, что в данной записи присутствуют поля только TS и Text.
4. Поле TS имеет тип D (очевидно целочисленная 32-х битовая). Читаем 02 00 00 00 (число - 2, наверное просто номер строки)
5. Поле Text имеет тип S (очевидно строка переменной длины). Поэтому читаем байт размера длины строки 01: - размер длины строки - 1 байт.
6. Читаем этот один байт 1E: длина строки - 30 байт.
7. Читаем 30 байт поля Text. Получаем строку: ==============================
8. Чтение записи завершено. Повторить с начала всех для последующих строк :)
С другими типами полей и методами их чтения - экспериментируем.
Очень жестокий вариант получается в таблицах каталога (файлы KAT*.*), для которых единый файл описания данных KATALOG.DDM. Его содержание в ETKA 7.5:
[FILE1]
fdt=Kataloge.fdt
[DDF]
cnt=35
1=AA,S ;Bildtafel
2=AB,S ;ET-Vor
3=AC,S ;Teilenummer
4=AD,S ;OU
5=AE,S ;BTPos
6=BA,I ;Einsatz
7=BB,I ;Auslauf
8=CA,S ;HG/UG
9=CB,S ;Grafik
10=DA,I ;TSBen
11=DE,S ;Benennung
12=DB,I ;TSBem
13=DF,S ;Bemerkung
14=DC,I ;TSMoa
15=DG,S ;Modellangabe
16=DD,S ;Stьck
17=DH,S ;TabET
18=C0,S ; PR-Nummer
19=C1,S ; Landessetzung
20=C2,S ; Baugruppen
21=C3,S ; Getriebekennbuchstaben
22=C4,S ; Ausstattungsvarianten
23=HF,S ; Farbkombi
24=HG,S ; MKB-4-stellig
25=IA,I ;Einsatz
26=IB,I ;Auslauf
27=JA,S ; MV
28=JC,S ; MV Tnr
29=JD,S ; MV Stk
30=KB,I ; PaktID
31=KC,S ; PaketArt
32=KD,I ; PaketStk
33=LA,S ; HTG
34=MA,I ; Bildtafel
35=MB,I ; Bildtafel
[GCX]
FeldDispLen=3400
fdt=Kataloge.fdt
[DDF]
cnt=35
1=AA,S ;Bildtafel
2=AB,S ;ET-Vor
3=AC,S ;Teilenummer
4=AD,S ;OU
5=AE,S ;BTPos
6=BA,I ;Einsatz
7=BB,I ;Auslauf
8=CA,S ;HG/UG
9=CB,S ;Grafik
10=DA,I ;TSBen
11=DE,S ;Benennung
12=DB,I ;TSBem
13=DF,S ;Bemerkung
14=DC,I ;TSMoa
15=DG,S ;Modellangabe
16=DD,S ;Stьck
17=DH,S ;TabET
18=C0,S ; PR-Nummer
19=C1,S ; Landessetzung
20=C2,S ; Baugruppen
21=C3,S ; Getriebekennbuchstaben
22=C4,S ; Ausstattungsvarianten
23=HF,S ; Farbkombi
24=HG,S ; MKB-4-stellig
25=IA,I ;Einsatz
26=IB,I ;Auslauf
27=JA,S ; MV
28=JC,S ; MV Tnr
29=JD,S ; MV Stk
30=KB,I ; PaktID
31=KC,S ; PaketArt
32=KD,I ; PaketStk
33=LA,S ; HTG
34=MA,I ; Bildtafel
35=MB,I ; Bildtafel
[GCX]
FeldDispLen=3400
Открываю файл KAT865.BIN, читаю записи и вижу, что размер битовой маски, указываемый в 3-ем байте, гуляет от 2 до 5 байт. Их в двоичный формат переводить в прямом порядке или обратно (BigEndian, LittleEndian)?
Почему в текстовых полях море мусора в виде управляющих символов? Я их заменяю на пробелы, но может в них есть какой-то глубокий смысл?
Цитата: Number
Опять появилась подобная задача(новый справочник), но старая проблема так и не решена. Хочу обновить алгоритм, но не нашел информации о том как определить - есть битовая маска в файле или нет. Те 2 байта, после числа колонок в fdt это номер группы файлов. Для каждой группы приходится руками ставить способ чтения. Из разных групп беру 2 таблицы. ddm, fdt у них подобны. Но в бин у одного, длина блока, длина маски и сама маска, а у другого сразу длина блока длина первого поля, значение и т.д. для остальных. Ведь должен быть более логичный способ определения, а не просматривать начало, каждого бинарника?
В заголовке файла *.FDT (первые 54 байта) читать второй байт после (шаблона) имени файла с данными:
- 4E (N) - нет битовой маски
- 49 (I), 00 - есть битовая маска
Цитата: elia
Почему в текстовых полях море мусора в виде управляющих символов? Я их заменяю на пробелы, но может в них есть какой-то глубокий смысл?
Отвечаю сам себе: это 1-байтовые поля с указанием длины следующей за ним подстроки. Данные хранятся в формате, удобном для вывода блоков на печать в репортах...
Цитата: bunak
Цитата: Sandulf
А никто не пробовал вместо разбора постоянно меняющегося формата БД разобраться с функциями LexDdm.dll в ETKA? Это ж по сути набор функций для работы с данной БД.
это если подключаться к ЕТКА то можно, а если нужно сливать в MySQL (т.е. максимально точно знать формат полей в таблице) - то все равно отслеживать придется
Надо подключаться тем или иным инструментом для связи баз данных. Но!
У Softwareag есть тестовая версия сервера для загрузки (под Винду!), но я ее для скачивания так получить и не смог - явно сайт и политики на нем писались в базе adabas и по идеологии этой системы :):):):):)
Есть сторонние инструменты для миграции, но у всех них есть две общие черты:
1) Хрен поймешь из описаний нужен ли сам adabas сервер для миграции или достаточно только файлов с данными?
2) Нет триальных версий и цены только по запросу в почте.
У Oracle есть Gateway для Adabas, но он требует установленного сервера Adabas и только на IBM z/OS...
В общем это все, связанное с Adabas, какая-то настолько замкнутая экосфера, что скорее всего нам остается только продолжать пилить свои просмоторщики этих файлов :)
Цитата: Lerkin
Перепишу дополненный вариант:
Код:
--------------------------------------------------------------------------------
Размер Описание
--------------------------------------------------------------------------------
3 байта Имя поля (ASCIIz)
2 байта Размер поля
2 байта Тип счетчика (ниже объясню)
2 байта Тип поля:
0x01: Superstruct (группа полей). Битовая маска накладывается на Superstruct целиком. В следующих строках указаны поля,
входящие в данную Superstruct.
0x02: Struct (поле разбито на субполя (subfields) для облегчения разметки вывода результатов). Битовая маска
накладывается на Struct целиком. Каждое субполе предваряется 2-байтным указателем его длины.
0x03: Обычное поле с данными
2 байта Счетчик количества полей, входящих в Superstruct
2 байта Тип данных в поле. Тут такая штука: типы заданы кодом. Вот некоторые, которые понял:
0x0a: беззнаковый символьный (unsigned char)
0x012: знаковый символьный (char)
0x14 и 0x16: знаковый целочисленный (int)
0x1a: Указатель на Superstruct (начало Superstruct и количество полей в ней, присутствующих в данной записи)
0x22: символьная строка, указанной длины (char[...])
0x26: Long int (только если внутри Superstruct?)
Соответственно, длина указана в "Размере поля"
Размер Описание
--------------------------------------------------------------------------------
3 байта Имя поля (ASCIIz)
2 байта Размер поля
2 байта Тип счетчика (ниже объясню)
2 байта Тип поля:
0x01: Superstruct (группа полей). Битовая маска накладывается на Superstruct целиком. В следующих строках указаны поля,
входящие в данную Superstruct.
0x02: Struct (поле разбито на субполя (subfields) для облегчения разметки вывода результатов). Битовая маска
накладывается на Struct целиком. Каждое субполе предваряется 2-байтным указателем его длины.
0x03: Обычное поле с данными
2 байта Счетчик количества полей, входящих в Superstruct
2 байта Тип данных в поле. Тут такая штука: типы заданы кодом. Вот некоторые, которые понял:
0x0a: беззнаковый символьный (unsigned char)
0x012: знаковый символьный (char)
0x14 и 0x16: знаковый целочисленный (int)
0x1a: Указатель на Superstruct (начало Superstruct и количество полей в ней, присутствующих в данной записи)
0x22: символьная строка, указанной длины (char[...])
0x26: Long int (только если внутри Superstruct?)
Соответственно, длина указана в "Размере поля"
А кто-нибудь разобрался с файлом tvn.bin?
Пытаюсь сделать поиск по TVN, и думаю что основная информация в этом файле, а именно ссылка на нужный kat файл.
Там три поля
1. Teilenummer - это сам номер запчасти
2. Index - ??
3. Bitmap
С первым поля всё ясно, а вот что делать с двумя другими ни как не пойму..
Кто разобрался, подкиньте пожалуйста идей или направления в каком копать.. Или может этот файл вообще не нужен для поиска TVN.
Заранее спасибо ...
Пытаюсь сделать поиск по TVN, и думаю что основная информация в этом файле, а именно ссылка на нужный kat файл.
Там три поля
1. Teilenummer - это сам номер запчасти
2. Index - ??
3. Bitmap
С первым поля всё ясно, а вот что делать с двумя другими ни как не пойму..
Кто разобрался, подкиньте пожалуйста идей или направления в каком копать.. Или может этот файл вообще не нужен для поиска TVN.
Заранее спасибо ...
Цитата: zje
А кто-нибудь разобрался с файлом tvn.bin?
Пытаюсь сделать поиск по TVN, и думаю что основная информация в этом файле, а именно ссылка на нужный kat файл.
Там три поля
1. Teilenummer - это сам номер запчасти
2. Index - ??
3. Bitmap
С первым поля всё ясно, а вот что делать с двумя другими ни как не пойму..
Кто разобрался, подкиньте пожалуйста идей или направления в каком копать.. Или может этот файл вообще не нужен для поиска TVN.
Заранее спасибо ...
Пытаюсь сделать поиск по TVN, и думаю что основная информация в этом файле, а именно ссылка на нужный kat файл.
Там три поля
1. Teilenummer - это сам номер запчасти
2. Index - ??
3. Bitmap
С первым поля всё ясно, а вот что делать с двумя другими ни как не пойму..
Кто разобрался, подкиньте пожалуйста идей или направления в каком копать.. Или может этот файл вообще не нужен для поиска TVN.
Заранее спасибо ...
1. Teilenummer - тип данных varchar
2. Index - тип данных tinyint (1b)
3. Bitmap - тип данных bytes (как и varchar состоит из указателя длины и данных)
Битовых масок нет, соответственно для полей переменной длины, в случае отсутствия данных, все равно стоит указатель с нулевым значением, а самого поля нет (так называемые suppressed nulls для экономии места)
Доброго времени суток! года 3 назад я распарсил каталог запчастей Lexcom. есть вопросы, задавайте, постараюсь вспомнить, ответить
Были каталоги сельскохозяйственных запчастей. Форматы файлов - .bin, .ddm, .fdt, .pnt
>> 2 байта Тип счетчика (ниже объясню)
Есть сложности с этим полем. Обычно оно имеет значение "0", но бывает ещё равно 0x64 для "суперструктур" и 0x1F4 которая работает как обёртка-множитель. Встречается в ETKA файл 08.bin. Кто копал?

Есть сложности с этим полем. Обычно оно имеет значение "0", но бывает ещё равно 0x64 для "суперструктур" и 0x1F4 которая работает как обёртка-множитель. Встречается в ETKA файл 08.bin. Кто копал?
Цитата: Aleksandr Aleksandr
>> 2 байта Тип счетчика (ниже объясню)
Есть сложности с этим полем. Обычно оно имеет значение "0", но бывает ещё равно 0x64 для "суперструктур" и 0x1F4 которая работает как обёртка-множитель. Встречается в ETKA файл 08.bin. Кто копал?
Есть сложности с этим полем. Обычно оно имеет значение "0", но бывает ещё равно 0x64 для "суперструктур" и 0x1F4 которая работает как обёртка-множитель. Встречается в ETKA файл 08.bin. Кто копал?
А какой смысл экспортировать данные из этого файла, где они используются?
Цитата: bunak
Цитата: Aleksandr Aleksandr
>> 2 байта Тип счетчика (ниже объясню)
Есть сложности с этим полем. Обычно оно имеет значение "0", но бывает ещё равно 0x64 для "суперструктур" и 0x1F4 которая работает как обёртка-множитель. Встречается в ETKA файл 08.bin. Кто копал?
Есть сложности с этим полем. Обычно оно имеет значение "0", но бывает ещё равно 0x64 для "суперструктур" и 0x1F4 которая работает как обёртка-множитель. Встречается в ETKA файл 08.bin. Кто копал?
А какой смысл экспортировать данные из этого файла, где они используются?
Используется или нет - ещё не знаю, но такое может встретиться в файле, который нужно будет разобрать. Ну и самое главное найти того, кто успешно раскопал формат. Ты раскопал? Интересуют пару всего пару моментов.
Цитата: Aleksandr Aleksandr
>> 2 байта Тип счетчика (ниже объясню)
Есть сложности с этим полем. Обычно оно имеет значение "0", но бывает ещё равно 0x64 для "суперструктур" и 0x1F4 которая работает как обёртка-множитель. Встречается в ETKA файл 08.bin. Кто копал?
Есть сложности с этим полем. Обычно оно имеет значение "0", но бывает ещё равно 0x64 для "суперструктур" и 0x1F4 которая работает как обёртка-множитель. Встречается в ETKA файл 08.bin. Кто копал?
Есть сомнения, что ты корректно распарсиваешь этот файл.
Вот например. Набросал парсер FDT и его помощью парсер bin файла. Но не сходится длина записей с определением. Добьём?
Там 36-е поле с именем MB имеет тип с кодом 18h, который не встречался. Первая запись в bin файле согласно полей в маске не укладывается в размеры установленные заголовком.
Цитата: Aleksandr Aleksandr
Используется или нет - ещё не знаю, но такое может встретиться в файле, который нужно будет разобрать. Ну и самое главное найти того, кто успешно раскопал формат. Ты раскопал? Интересуют пару всего пару моментов.
Этот файл не выгружал. Вы пока пропустите эти файлы, а когда встретитесь с подобным в других файлах то отпишитесь понову.
KatXXX.bin - это каталоги запчастей, мне от них никуда. Остальные были простые, я бы не писал.
Зачем выгружать все подряд не зная для чего их применять? Если бы Вы определили в каких местах ETKA использует эти файлы я готов помочь с ними.
Цитата: bunak
Зачем выгружать все подряд не зная для чего их применять? Если бы Вы определили в каких местах ETKA использует эти файлы я готов помочь с ними.
каталоги запчастей, один каталог - одна марка авто
А какие файлы смотрел? Какие форматы данных опознал? Разобрал Overview? Разобрал Stamm?
Есть такой прикол, что указатели из PNT указывают на данные конкретного размера и между записями есть другие данные, формат вроде не бьётся по FDT.
Есть такой прикол, что указатели из PNT указывают на данные конкретного размера и между записями есть другие данные, формат вроде не бьётся по FDT.
Цитата: Aleksandr Aleksandr
А какие файлы смотрел? Какие форматы данных опознал? Разобрал Overview? Разобрал Stamm?
Есть такой прикол, что указатели из PNT указывают на данные конкретного размера и между записями есть другие данные, формат вроде не бьётся по FDT.
Есть такой прикол, что указатели из PNT указывают на данные конкретного размера и между записями есть другие данные, формат вроде не бьётся по FDT.
по FDT во многих местах будут ошибки
Цитата: Aleksandr Aleksandr
Вот например. Набросал парсер FDT и его помощью парсер bin файла. Но не сходится длина записей с определением. Добьём?
Александр, получилось добить скрипты? Может, выложите? Будем править...
Цитата: lsvmo
Цитата: Aleksandr Aleksandr
Вот например. Набросал парсер FDT и его помощью парсер bin файла. Но не сходится длина записей с определением. Добьём?
Александр, получилось добить скрипты? Может, выложите? Будем править...
Добил, но проект уже сдан.
Используй AdabasFDT.bt, он почти идеален.
Цитата: lsvmo
Цитата: Aleksandr Aleksandr
Вот например. Набросал парсер FDT и его помощью парсер bin файла. Но не сходится длина записей с определением. Добьём?
Александр, получилось добить скрипты? Может, выложите? Будем править...
Тут в теме очень много подсказок, внимательно прочтите все разберетесь.
Aleksandr Aleksandr, вы разобрались где файлы аля "08.bin" используются?
Цитата: Aleksandr Aleksandr
[quote=lsvmo;79134]Добил, но проект уже сдан.
Используй AdabasFDT.bt, он почти идеален.
Используй AdabasFDT.bt, он почти идеален.
Если осилишь использование самого Adabas :)
Software AG - яркий пример сумрачного тевтонского гения. Сплошной хардкор даже с восстановлением доступа к их сайтам.
Цитата: elia
Если осилишь использование самого Adabas :)
Software AG - яркий пример сумрачного тевтонского гения. Сплошной хардкор даже с восстановлением доступа к их сайтам.
Александр скорее всего имел ввиду что в его файле уже реализовано разбор типов полей
Подскажите, пожалуйста, не могу сообразить.
По отдельности структура файлов вроде понятна, но как они связаны. Перечитал ветку раз 7.
Во вложении картинки.
Как соотносятся "Типы и размеры полей" (из описания структур выше) с файлом .bin?
А также информация в "Ещё один блок (описание полей") с файлом .bin?
В файлах во вложении есть поле с размером 19h, но в bin файле такого размера нет.
И следующее поле с размером FFh тоже не пойму, где в bin файле.
А также по маске используются 4 поля, но при разборе в первой записи после VERS.VERS идёт длина 08, но потом какая-то 01h идёт перед 09h F-09/2014, и вот эта 01h никуда не вписывается.
Может, сталкивались с параметром типа "B" - просто набор байт?
Если возможно - распишите, пожалуйста, одну запись из файлов во вложении , со связями значений в файлах ddm, fdt, bin
По отдельности структура файлов вроде понятна, но как они связаны. Перечитал ветку раз 7.
Во вложении картинки.
Как соотносятся "Типы и размеры полей" (из описания структур выше) с файлом .bin?
А также информация в "Ещё один блок (описание полей") с файлом .bin?
В файлах во вложении есть поле с размером 19h, но в bin файле такого размера нет.
И следующее поле с размером FFh тоже не пойму, где в bin файле.
А также по маске используются 4 поля, но при разборе в первой записи после VERS.VERS идёт длина 08, но потом какая-то 01h идёт перед 09h F-09/2014, и вот эта 01h никуда не вписывается.
Может, сталкивались с параметром типа "B" - просто набор байт?
Если возможно - распишите, пожалуйста, одну запись из файлов во вложении , со связями значений в файлах ddm, fdt, bin
Ладно :-)
вопрос тогда в другом.
Когда уже понятна структура каждой отдельной базы, как понять, как они связаны?
Как связать информацию из одной связки (fdt, bin,pnt) с другой связкой fdt, bin,pnt.
Хотя бы направьте в нужную сторону :-)
вопрос тогда в другом.
Когда уже понятна структура каждой отдельной базы, как понять, как они связаны?
Как связать информацию из одной связки (fdt, bin,pnt) с другой связкой fdt, bin,pnt.
Хотя бы направьте в нужную сторону :-)
Цитата: lsvmo
Ладно :-)
вопрос тогда в другом.
Когда уже понятна структура каждой отдельной базы, как понять, как они связаны?
Как связать информацию из одной связки (fdt, bin,pnt) с другой связкой fdt, bin,pnt.
Хотя бы направьте в нужную сторону :-)
вопрос тогда в другом.
Когда уже понятна структура каждой отдельной базы, как понять, как они связаны?
Как связать информацию из одной связки (fdt, bin,pnt) с другой связкой fdt, bin,pnt.
Хотя бы направьте в нужную сторону :-)
Только методом малонаучного тыка :) Реверс-инжиниринг структуры базы данных без документации на нее по-другому никак не сделаешь.
Цитата: lsvmo
Ладно :-)
вопрос тогда в другом.
Когда уже понятна структура каждой отдельной базы, как понять, как они связаны?
Как связать информацию из одной связки (fdt, bin,pnt) с другой связкой fdt, bin,pnt.
Хотя бы направьте в нужную сторону :-)
вопрос тогда в другом.
Когда уже понятна структура каждой отдельной базы, как понять, как они связаны?
Как связать информацию из одной связки (fdt, bin,pnt) с другой связкой fdt, bin,pnt.
Хотя бы направьте в нужную сторону :-)
Отследить, ProcessMon в помощь
Спасибо всем за информацию и советы, предоставленные в этой ветке!
Только благодаря им удалось открыть базу данных и расшифровать изображения программы etka.
Запнулся на координатах, которые хранятся в конце файла с картинкой.
Буду благодарен, если кто-нибудь хотя бы намекнет, в чем там хитрость!
Только благодаря им удалось открыть базу данных и расшифровать изображения программы etka.
Запнулся на координатах, которые хранятся в конце файла с картинкой.
Буду благодарен, если кто-нибудь хотя бы намекнет, в чем там хитрость!
Цитата: runeseeker
Спасибо всем за информацию и советы, предоставленные в этой ветке!
Только благодаря им удалось открыть базу данных и расшифровать изображения программы etka.
Запнулся на координатах, которые хранятся в конце файла с картинкой.
Буду благодарен, если кто-нибудь хотя бы намекнет, в чем там хитрость!
Только благодаря им удалось открыть базу данных и расшифровать изображения программы etka.
Запнулся на координатах, которые хранятся в конце файла с картинкой.
Буду благодарен, если кто-нибудь хотя бы намекнет, в чем там хитрость!
Позиция пикселя угла номера части и количество пикселей по горизонтали и вертикали, что-то типа того
Цитата: Dmi
Позиция пикселя угла номера части и количество пикселей по горизонтали и вертикали, что-то типа того
Спасибо за ответ! Разобрался.
У нас на сайте все проститутки с видео из Москвы проведут с вами незабываемое время вашего досуга.

У нас на сайте все проститутки с видео из Москвы проведут с вами незабываемое время вашего досуга.
Это для тех, кто ниасилил с базой данных.
Дабы быть благодарным тем, кто здесь всё так подробно описал, также добавлю то, что может помочь.
Pnt-файлы нужны для организации поиска по дереву, то есть сравниваются значения ключей в pnt-файле на больше-меньше и потом уходим в ту половину файла, куда приведёт это сравнение. Когда найдём нужный ключ - в этой записи есть смещение внутри файла BIN на эту запись (последние 4 байта). Длина записи в pnt-файле при этом считывается из fdt-файла по смещению 0x24.
Строковые поля могут быть разного вида.
(длина поля, байты строки на всю длину поля) - то есть сразу идти за полем длины
(длина поля, 01 03 (4 байта Key-ссылка D4duden-базу строк) 01 03 - то есть открываться и закрываться тэгом <01 03>, а между ними ссылка на строку
(длина поля, байты строки, 01 03 (4 байта Key-ссылка D4duden-базу строк) 01 03, байты строки и т.п., то есть непосредственно байты строки конкатенироваться со строками, получаемыми из ссылок на D4Duden и так подряд друг за другом
Есть ещё вид
01 07 байты строки 01 08 байты строки 01 07 - не совсем понятно, но за 01 08 может быть строка или строка в тэгах 01 03
00 0B - может встречаться и такая комбинация (внутри строки , как управляющие байты), но она нужна уже для разделения внутри строки для нужд самой программы
Что касается разбора записей в BIN-файлах.
Как описано ранее в ветке форума - разбираем на общиго вида блоки. А дальше первый байт после полей ключей - идёт число подполей данных. После этого уже (длина,подполе), (длина,подполе).
Что касается координат в конце рисунка.
Есть файлы tiff и есть файлы jpg.
Для jpg-файлов - можно пробежаться с самого начала по блокам с их длинами (см. формат файла jpg) или просто с конца пробежаться вверх и найти байты FF D9 - это конец файла jpg, после них идут
4 байта - сколько сколько записей координат идёт дальше.
Одна запись следующего вида:
4 байта - X верхнего левого угла
4 байта - Y верхнего левого угла
4 байта - X правого ниженго угла
4 байта - Y правого нижнего угла,
4 байта - длина цифры в виде строки (н-р, цифра 9 - это в символах 39 00, поэтому длина будет 02 00 00 00, если цифра 10, то длина - 03 00 00 00)
(строка с цифрой длиной из предыдущего поля),
2 байта - не понятно для чего, но определяет число полей длиной 4 байта после этого поля,
(4-байтовые поля) - сколько их указано в предыдущем поле.
Для tiff-файлов - в заголовке файла 4 байта по смещению 4 определяют длину tiff-файла. После этой длины идёт блок координат следующего вида.
там два блока:
первый - содержит информацию о цифрах на картинке, при этом, так как цифры могут повторяться на картинке, в этом блоке они не повторяются ( то есть первый блок содержит мета-информацию , а второй блок уже может содержать разные координаты для разных цифр)
второй - координаты для отображаемых цифр (цифры могут повторяться, координаты нет)
2 байта - количество записей в первом блоке. Это число равно - количество использованых цифр + 3. Число 3 появляется так как две записи для размера картинки в пикселях, и одна для указания смещения второго блока.
Одна запись вида (кроме первой, второй и последней)
байт - номер (увеличивается от записи к записи, но не предсказуемо)
два байта - не понятно, но имеют вид 01 03 (или 01 02 и т.п.)
1 байт - 00 (не понятно зачем)
4 байта - сколько раз цифра встречается на картинке
4 байта - данные по картинке.
В первом блоке, особое назначение следующих записей:
первые две записи - размер картинки в пикселях (в поле данных)
последняя запись - количество записей во втором блоке (поле "сколько раз") и смещение в файле на начало второго блока с координатами (поле с данными)
После этого блока (массива записей ) идут 20 байт не ясно для чего.
А потом начинается второй блок.
Второй блок с координатами следующего вида.
два байта - длина записи (включая байты длины)
два байта - X (угла прямоугольника координат)
два байта - Y
два байта - ширина (прямоугольника вокруг цифры)
два байта - высота
один байт - длина строки с цифрой в символьном виде
строка длиной, указанной выше (но учесть, что ещё завершающий ноль, почему-то здесь, в отличие от других мест, он явно не учитывается в длине)
оставшиеся байты
Во вложении скрипты для разбора.
Если кто подскажет про устройство подробнее, и назначение полей (может, ошибся), скажу спасибо :-)
Pnt-файлы нужны для организации поиска по дереву, то есть сравниваются значения ключей в pnt-файле на больше-меньше и потом уходим в ту половину файла, куда приведёт это сравнение. Когда найдём нужный ключ - в этой записи есть смещение внутри файла BIN на эту запись (последние 4 байта). Длина записи в pnt-файле при этом считывается из fdt-файла по смещению 0x24.
Строковые поля могут быть разного вида.
(длина поля, байты строки на всю длину поля) - то есть сразу идти за полем длины
(длина поля, 01 03 (4 байта Key-ссылка D4duden-базу строк) 01 03 - то есть открываться и закрываться тэгом <01 03>, а между ними ссылка на строку
(длина поля, байты строки, 01 03 (4 байта Key-ссылка D4duden-базу строк) 01 03, байты строки и т.п., то есть непосредственно байты строки конкатенироваться со строками, получаемыми из ссылок на D4Duden и так подряд друг за другом
Есть ещё вид
01 07 байты строки 01 08 байты строки 01 07 - не совсем понятно, но за 01 08 может быть строка или строка в тэгах 01 03
00 0B - может встречаться и такая комбинация (внутри строки , как управляющие байты), но она нужна уже для разделения внутри строки для нужд самой программы
Что касается разбора записей в BIN-файлах.
Как описано ранее в ветке форума - разбираем на общиго вида блоки. А дальше первый байт после полей ключей - идёт число подполей данных. После этого уже (длина,подполе), (длина,подполе).
Что касается координат в конце рисунка.
Есть файлы tiff и есть файлы jpg.
Для jpg-файлов - можно пробежаться с самого начала по блокам с их длинами (см. формат файла jpg) или просто с конца пробежаться вверх и найти байты FF D9 - это конец файла jpg, после них идут
4 байта - сколько сколько записей координат идёт дальше.
Одна запись следующего вида:
4 байта - X верхнего левого угла
4 байта - Y верхнего левого угла
4 байта - X правого ниженго угла
4 байта - Y правого нижнего угла,
4 байта - длина цифры в виде строки (н-р, цифра 9 - это в символах 39 00, поэтому длина будет 02 00 00 00, если цифра 10, то длина - 03 00 00 00)
(строка с цифрой длиной из предыдущего поля),
2 байта - не понятно для чего, но определяет число полей длиной 4 байта после этого поля,
(4-байтовые поля) - сколько их указано в предыдущем поле.
Для tiff-файлов - в заголовке файла 4 байта по смещению 4 определяют длину tiff-файла. После этой длины идёт блок координат следующего вида.
там два блока:
первый - содержит информацию о цифрах на картинке, при этом, так как цифры могут повторяться на картинке, в этом блоке они не повторяются ( то есть первый блок содержит мета-информацию , а второй блок уже может содержать разные координаты для разных цифр)
второй - координаты для отображаемых цифр (цифры могут повторяться, координаты нет)
2 байта - количество записей в первом блоке. Это число равно - количество использованых цифр + 3. Число 3 появляется так как две записи для размера картинки в пикселях, и одна для указания смещения второго блока.
Одна запись вида (кроме первой, второй и последней)
байт - номер (увеличивается от записи к записи, но не предсказуемо)
два байта - не понятно, но имеют вид 01 03 (или 01 02 и т.п.)
1 байт - 00 (не понятно зачем)
4 байта - сколько раз цифра встречается на картинке
4 байта - данные по картинке.
В первом блоке, особое назначение следующих записей:
первые две записи - размер картинки в пикселях (в поле данных)
последняя запись - количество записей во втором блоке (поле "сколько раз") и смещение в файле на начало второго блока с координатами (поле с данными)
После этого блока (массива записей ) идут 20 байт не ясно для чего.
А потом начинается второй блок.
Второй блок с координатами следующего вида.
два байта - длина записи (включая байты длины)
два байта - X (угла прямоугольника координат)
два байта - Y
два байта - ширина (прямоугольника вокруг цифры)
два байта - высота
один байт - длина строки с цифрой в символьном виде
строка длиной, указанной выше (но учесть, что ещё завершающий ноль, почему-то здесь, в отличие от других мест, он явно не учитывается в длине)
оставшиеся байты
Во вложении скрипты для разбора.
Если кто подскажет про устройство подробнее, и назначение полей (может, ошибся), скажу спасибо :-)