
class MyThread : public QThread
{
Q_OBJECT
int* Buff;
int l;
int r;
QSemaphore *s;
void sort(int* Buff, int l, int r)
{
bool a = false;
bool b = false;
int i=l;
int j=r;
int x=Buff[(l+r)/2];
do
{
while(Buff<x) ++i;
while(Buff[j]>x) --j;
if(i<=j)
{
std::swap(Buff,Buff[j]);
i++; j--;
}
} while(i<=j);
//если есть свободные ресурсы
if(l<j && s->tryAcquire())
{
a = true;
MyThread* t = new MyThread(Buff,l,j,s);
t->start();
}
if(i<r && s->tryAcquire())
{
b = true;
MyThread* t = new MyThread(Buff,i,r,s);
t->start();
}
//если нет свободных ресурсов
//a,b - чтобы знать, не запустилась ли какая из сортировок раньше
if (l<j && !a)
sort(Buff,l,j);
if(i<r && !b)
sort(Buff,i,r);
}
public:
MyThread(int* _Buff, int _l, int _r, QSemaphore* _s):Buff(_Buff),l(_l),r(_r)
{
s = _s;
}
void run()
{
sort(Buff,l,r);
s->release();
}
};
class _Sort
{
public:
static int qSort(int* Buff, size_t Size, quint32 ThreadCount)
{
if (Buff == NULL || Size <= 1 ||
((ThreadCount & (ThreadCount-1)) != 0))
{
qDebug() << "Error in params";
return 1;
}
QSemaphore *sem = new QSemaphore(ThreadCount);
sem->acquire();
MyThread* t = new MyThread(Buff,0, Size-1,sem);
t->start();
while(static_cast<quint32>(sem->available()) != ThreadCount);
delete sem;
return 0;
}
static void qSortOneThread(int* Buff, int l, int r)
{
int i=l;
int j=r;
int x=Buff[(l+r)/2];
do
{
while(Buff<x) ++i;
while(Buff[j]>x) --j;
if(i<=j)
{
std::swap(Buff,Buff[j]);
i++; j--;
}
} while(i<=j);
if(l<j)
qSortOneThread(Buff,l,j);
if(i<r)
qSortOneThread(Buff,i,r);
}
};
Qt распараллеливание сортировки
Доброго.
qSortOneThread - один поток.
qSort - несколько потоков. В моём случае 2.
Результаты:
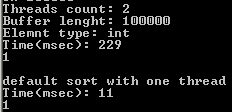
229мс - это очень плохой результат. Мне нужно, чтобы распараллеленная была хотя бы на 0,25 быстрее однопоточной. Думаю, что такие результаты из-за дополнительных расходов на создание потока, всё-таки в рекурсии повторный вызов функции выполняется быстрее.
Есть какие-нибудь соображения, что можно изменить, чтобы ускорить многопоточную сортировку?
Код:
qSortOneThread - один поток.
qSort - несколько потоков. В моём случае 2.
Результаты:
229мс - это очень плохой результат. Мне нужно, чтобы распараллеленная была хотя бы на 0,25 быстрее однопоточной. Думаю, что такие результаты из-за дополнительных расходов на создание потока, всё-таки в рекурсии повторный вызов функции выполняется быстрее.
Есть какие-нибудь соображения, что можно изменить, чтобы ускорить многопоточную сортировку?
О Аллах, подари программистам под Windows нормальный профайлер. Что-то ни gprof, ни Sleepy не отображают нормально данные. Один показывает имена функций, но не показывает время, второй делает всё с точностью наоборот.
Уже не думаю, что дело именно в создании нового потока, простые замеры показали, что это быстрее миллисекунды. Но это без инициализации переменных.Что тогда ест ресурсы?
Уже не думаю, что дело именно в создании нового потока, простые замеры показали, что это быстрее миллисекунды. Но это без инициализации переменных.Что тогда ест ресурсы?
была похожая ситуация, только параллелил алгоритм на графе. когда в цикле создавал потоки тормозило страшно, потом решил задачу через пулл потоков, просто взлетела. Поставь переменную счеткик в тело функции потока и посмотри сколько раз создавались потоки за время работы.
Цитата: bolt7
была похожая ситуация, только параллелил алгоритм на графе. когда в цикле создавал потоки тормозило страшно, потом решил задачу через пулл потоков, просто взлетела. Поставь переменную счеткик в тело функции потока и посмотри сколько раз создавались потоки за время работы.
Не очень много. Раз 14. У меня ограничение на количество одновременно запущенных потоков через семафор. Уже нашёл, где ресурсы съедаются. Вот тут:
Код:
while(static_cast<quint32>(sem->available()) != ThreadCount);
Если семафоры потокобезопасны, думаю, каждый раз, вызывая этот метод, все остальные потоки притормаживаются. Долго пришлось доходить до этого без профайлера, но, если вставить в тело цикла штук 5 QThread::YealCurrentThread, то скорость повышается, но всё равно недостаточно. А с увеличением количества одновременных потоков, увеличивается и разрыв во времени. Получается миллесекунд на 50-70 медленнее однопоточной. Сейчас попытаюсь через таймер отложить вызов проверки на более долгое время, может, поможет. Пулл потоков - это QThreadPool? Если да, то я от него отказался. Он был самым тормозным вариантом из всех, раз в 20 медленнее того, что есть сейчас.
UPD: сделать вызов проверки отложенным через слот не получилось, не хотелось бы делать метод не статическим.
если 14 раз то из-за потоков, самой системе сколько нужно ресурсов сожрать для создания нового потока + тут еще отельный класс. Я не знаю что там за QThreadPool, я не программировал на qt к тому же вообще не люблю ООП, пул не должен тормозить, по крайней мере системный, это наверное такая крутая реализация в среде.
Сейчас попробую...
Сейчас попробую...
Скорость немного увеличилась с использованием QWaitCondition, даже был прирост по сравнению с однопоточной, но добавление QMutexLocker сожрало много ресурсов и производительность упала. Придётся писать профайлер и смотреть, где основная утечка. Умные люди намекают, что дело в плохом алгоритме.
Кстати, замерил создание одного пустого потока без каких-либо действий внутри. Меньше 1 мс оказалось. Где-то есть цикл, который сжирает ресурс.
Кстати, замерил создание одного пустого потока без каких-либо действий внутри. Меньше 1 мс оказалось. Где-то есть цикл, который сжирает ресурс.
у меня тоже тормозит, из за того что с каждым разом подмассив уменьшается то смысла нет его вешать на отдельный поток и излишки служебных опраций тянут время.
вот посмотри ссылку и вывод прочти http://suvitruf.ru/2011/10/01/594/
вот посмотри ссылку и вывод прочти http://suvitruf.ru/2011/10/01/594/
Цитата: bolt7
у меня тоже тормозит, из за того что с каждым разом подмассив уменьшается то смысла нет его вешать на отдельный поток и излишки служебных опраций тянут время.
вот посмотри ссылку и вывод прочти http://suvitruf.ru/2011/10/01/594/
вот посмотри ссылку и вывод прочти http://suvitruf.ru/2011/10/01/594/
По ссылке. Решил попробовать тот алгоритм, что там написан. И вот что меня чуточку смущает:
Код:
while ((Params->left<supporting) && (mas[Params->left]<=mas[supporting]))
Params->left++;
while ((Params->right>supporting) && (mas[Params->right]>=mas[supporting]))
Params->right--;
Params->left++;
while ((Params->right>supporting) && (mas[Params->right]>=mas[supporting]))
Params->right--;
А дальше:
Код:
if (Params->left == supporting ) supporting = Params->right;
else if (Params->right == supporting ) supporting = Params->left;
else if (Params->right == supporting ) supporting = Params->left;
По-хорошему, этот код не должен никогда заработать, что у меня и случилось. Автор, должно быть, ошибся. Хотя остальная часть реализации вызывает падение программы. Может, там тоже ошибка, а, может, я реализовал логику немного неверно. Копаюсь, в общем.
Не получилось сделать с динамическим созданием потоков по необходимости. Тратится слишком много ресурсов на опрос семафора для создания нового потока. Если сделать один поток и убрать опрос семафора, то производительность на том же уровне, что и у не распараллеленной. Я там такое условие наворотил, что из массива в 2000к элементов семафор опрашивается только 200000к раз, но всё равно это много. Посему буду сразу создавать нужное количество потоков до начала сортировки и как-то передавать между ними данные. Появилось несколько вопросов:
1) Как узнавать, какой поток освободился? Пока что подумал в сторону передачи параметром массива bool, где каждый поток будет отмечать, работает он или нет. Но это не очень хороший вариант, как мне кажется. Да и как данные синхронизировать тоже не представлю. Пробовал реализацию с очередью, но она тратила ресурсов ещё больше, чем семафоры.
2) Как поток, который породил все остальные(а он не основной), должен узнавать, что сортировка завершена? Пока что использую QWaitCondition, но что-то в нём меня смущает. Может, не очень хорошая реализация условия о завершении всех потоков, но, по-моему, по производительности это было почти так же, как обычный цикл, поток не спал достаточно, что странно.
Что-то совсем ничего не клеится с этой сортировкой и почитать об этом не знаю где. Своих идей пока что нет.
1) Как узнавать, какой поток освободился? Пока что подумал в сторону передачи параметром массива bool, где каждый поток будет отмечать, работает он или нет. Но это не очень хороший вариант, как мне кажется. Да и как данные синхронизировать тоже не представлю. Пробовал реализацию с очередью, но она тратила ресурсов ещё больше, чем семафоры.
2) Как поток, который породил все остальные(а он не основной), должен узнавать, что сортировка завершена? Пока что использую QWaitCondition, но что-то в нём меня смущает. Может, не очень хорошая реализация условия о завершении всех потоков, но, по-моему, по производительности это было почти так же, как обычный цикл, поток не спал достаточно, что странно.
Что-то совсем ничего не клеится с этой сортировкой и почитать об этом не знаю где. Своих идей пока что нет.
Делал когда то в институте один матричный алгоритм. и в цикле создавал потоки. Все вроде бы так красиво было, короче думал всех порву. Какое было мое удивление когда тип один принес на жабе херню какуету и она работала в десятки раз быстрее! потом моя прога его сделала конечно, и щас раскажу как.
Создаем заранее нужное количество потоков.
Потом два массива с событиями (за имена переменных звиняйте, тогда всегда так писал а,б,в ...:)))
Потом делаю тот же цикл но вместо того чтоб создавать новый поток, жду свободный
Функция потока
теперь вспомнил, поглощения столбцов.
Объяснения
массив евентов mut служил для хранения статусов потоков. когда поток освободился он переводит свой евент в свободное состояние.
mut1 - ожидание потоком выдачи задачи, когда евент переходит в свободное состояние то потоку дали работу. Каждому потоку передавался его индекс в массивах.
в цикле главная программа ожидает когда освободится хотябы один поток, передает ему каким то образом параметры (я делал через глобальную память) и устанавливает его событие mut1 в свободное. В это время все потоки спят (mut1 создаются сразу в занятом состоянии) и просыпается только тот которому освободили евент, тоесть дали работу. после окончания обработки он сбрасывает евент в другом масиве mut и засыпает. правда стобцы то одинаково размера а тут массивы уменьшаются все время. Можно вместо евентов использовать любые другие обьекты синхронизации, но я бы посоветовал пока попробовать виндовские апи, а не библиотечные
Создаем заранее нужное количество потоков.
Код:
for (int i = 0; i < N; i++)
CreateThread(0, 0, (LPTHREAD_START_ROUTINE)ThreadProc, (LPVOID)i, 0, 0);
CreateThread(0, 0, (LPTHREAD_START_ROUTINE)ThreadProc, (LPVOID)i, 0, 0);
Потом два массива с событиями (за имена переменных звиняйте, тогда всегда так писал а,б,в ...:)))
Код:
for (int i = 0; i < N; i++)
mut = CreateEvent(0, 0, 1, 0);
for (int i = 0; i < N; i++)
mut1 = CreateEvent(0, 0, 0, 0);
mut = CreateEvent(0, 0, 1, 0);
for (int i = 0; i < N; i++)
mut1 = CreateEvent(0, 0, 0, 0);
Потом делаю тот же цикл но вместо того чтоб создавать новый поток, жду свободный
Код:
ind = WaitForMultipleObjects(N, mut, 0, INFINITE);
//передаем параметры
SetEvent(mut1[ind]);
//передаем параметры
SetEvent(mut1[ind]);
Функция потока
Код:
VOID WINAPI ThreadProc(LPVOID lpParameter) {
DWORD ind = (DWORD)lpParameter;
while (1) {
WaitForSingleObject(mut1[ind], INFINITE);
absorp(tab, a1[ind], b1[ind]);
SetEvent(mut[ind]);
}
}
}
DWORD ind = (DWORD)lpParameter;
while (1) {
WaitForSingleObject(mut1[ind], INFINITE);
absorp(tab, a1[ind], b1[ind]);
SetEvent(mut[ind]);
}
}
}
теперь вспомнил, поглощения столбцов.
Объяснения
массив евентов mut служил для хранения статусов потоков. когда поток освободился он переводит свой евент в свободное состояние.
mut1 - ожидание потоком выдачи задачи, когда евент переходит в свободное состояние то потоку дали работу. Каждому потоку передавался его индекс в массивах.
в цикле главная программа ожидает когда освободится хотябы один поток, передает ему каким то образом параметры (я делал через глобальную память) и устанавливает его событие mut1 в свободное. В это время все потоки спят (mut1 создаются сразу в занятом состоянии) и просыпается только тот которому освободили евент, тоесть дали работу. после окончания обработки он сбрасывает евент в другом масиве mut и засыпает. правда стобцы то одинаково размера а тут массивы уменьшаются все время. Можно вместо евентов использовать любые другие обьекты синхронизации, но я бы посоветовал пока попробовать виндовские апи, а не библиотечные
2bolt7
Парсер пожрал индексирующие скобки у массивов?
Переписал на WinApi вчера и, что удивительно, прироста производительности нет.
Сейчас схема такая:
Запускается новый поток, который разбивает массив на два подмассива. Создаётся ещё один поток, в котором рекурсивно сортируется один подмассив, а второй подмассив сортируется рекурсивно на месте. То есть, два потока всего.
Удивительно, что такая схема не даёт никакого ускорения по сравнению с однопоточной сортировкой.
Вообще, у процессора какая-то странная активность в момент сортировки. Если весь процесс повесить только на одно ядро, то второе ядро не загружается системой вообще. Если на два ядра, то в момент не параллельной сортировки второе ядро грузится на ~50%, первое на ~80-90%. В момент начала параллельной сортировки первое ядро грузится так же, как и в прошлом случае, а второе ядро секунды на 4 грузится на 100%, а потом снова загрузка падает до 50%, как в случае с не параллельной сортировкой. От чего так - ума не приложу. Вот немного кода:
В основной функции вызывается qSort для нескольких потоков и qSortOneThread для одного - рекурсивная реализация. Она потом вызывается и в созданном потоке, после того, как массив будет разделён на две половины в qSort,
Парсер пожрал индексирующие скобки у массивов?
Переписал на WinApi вчера и, что удивительно, прироста производительности нет.
Сейчас схема такая:
Запускается новый поток, который разбивает массив на два подмассива. Создаётся ещё один поток, в котором рекурсивно сортируется один подмассив, а второй подмассив сортируется рекурсивно на месте. То есть, два потока всего.
Удивительно, что такая схема не даёт никакого ускорения по сравнению с однопоточной сортировкой.
Вообще, у процессора какая-то странная активность в момент сортировки. Если весь процесс повесить только на одно ядро, то второе ядро не загружается системой вообще. Если на два ядра, то в момент не параллельной сортировки второе ядро грузится на ~50%, первое на ~80-90%. В момент начала параллельной сортировки первое ядро грузится так же, как и в прошлом случае, а второе ядро секунды на 4 грузится на 100%, а потом снова загрузка падает до 50%, как в случае с не параллельной сортировкой. От чего так - ума не приложу. Вот немного кода:
Код:
class _Sort
{
struct sortParams
{
int* buff;
quint64 l;
quint64 r;
sortParams(int* Buff, quint64 L, quint64 R): buff(Buff),l(L),r(R) {}
};
static DWORD WINAPI sortLocal4Threads(LPVOID P)
{
sortParams* p = static_cast<sortParams*>(P);
_Sort::qSortOneThread(p->buff,p->l,p->r);
return 0;
}
public:
static void qSortOneThread(int* Buff, quint64 l, quint64 r)
{
quint64 i=l;
quint64 j=r;
int x=Buff[(l+r)/2];
do
{
while(Buff<x) ++i;
while(Buff[j]>x) --j;
if(i<=j)
{
std::swap(Buff,Buff[j]);
i++;
j--;
}
}
while(i<=j);
if(l<j)
qSortOneThread(Buff,l,j);
if(i<r)
qSortOneThread(Buff,i,r);
}
static int qSort(int* Buff, size_t Size, quint32 ThreadCount)
{
if (Buff == NULL)
{
std::cout << "Pointer to buffer is NULL" <<std::endl;
return 1;
}
quint64 i=0;
quint64 j=Size-1;
int x=Buff[(i+j)/2];
do
{
while(Buff<x) ++i;
while(Buff[j]>x) --j;
if(i<=j)
{
std::swap(Buff,Buff[j]);
i++;
j--;
}
}
while(i<=j);
HANDLE hThread;
sortParams param(Buff,0,j);
DWORD idThread;
hThread = CreateThread(NULL,0,_Sort::sortLocal4Threads,¶m,0,&idThread);
if (hThread == NULL)
{
std::cout << "Error while thread creation with code " << GetLastError()<<std::endl;
return 1;
}
qSortOneThread(Buff,i,Size-1);
WaitForSingleObject(hThread,INFINITE);
return 0;
}
};
{
struct sortParams
{
int* buff;
quint64 l;
quint64 r;
sortParams(int* Buff, quint64 L, quint64 R): buff(Buff),l(L),r(R) {}
};
static DWORD WINAPI sortLocal4Threads(LPVOID P)
{
sortParams* p = static_cast<sortParams*>(P);
_Sort::qSortOneThread(p->buff,p->l,p->r);
return 0;
}
public:
static void qSortOneThread(int* Buff, quint64 l, quint64 r)
{
quint64 i=l;
quint64 j=r;
int x=Buff[(l+r)/2];
do
{
while(Buff<x) ++i;
while(Buff[j]>x) --j;
if(i<=j)
{
std::swap(Buff,Buff[j]);
i++;
j--;
}
}
while(i<=j);
if(l<j)
qSortOneThread(Buff,l,j);
if(i<r)
qSortOneThread(Buff,i,r);
}
static int qSort(int* Buff, size_t Size, quint32 ThreadCount)
{
if (Buff == NULL)
{
std::cout << "Pointer to buffer is NULL" <<std::endl;
return 1;
}
quint64 i=0;
quint64 j=Size-1;
int x=Buff[(i+j)/2];
do
{
while(Buff<x) ++i;
while(Buff[j]>x) --j;
if(i<=j)
{
std::swap(Buff,Buff[j]);
i++;
j--;
}
}
while(i<=j);
HANDLE hThread;
sortParams param(Buff,0,j);
DWORD idThread;
hThread = CreateThread(NULL,0,_Sort::sortLocal4Threads,¶m,0,&idThread);
if (hThread == NULL)
{
std::cout << "Error while thread creation with code " << GetLastError()<<std::endl;
return 1;
}
qSortOneThread(Buff,i,Size-1);
WaitForSingleObject(hThread,INFINITE);
return 0;
}
};
В основной функции вызывается qSort для нескольких потоков и qSortOneThread для одного - рекурсивная реализация. Она потом вызывается и в созданном потоке, после того, как массив будет разделён на две половины в qSort,
Немного попрофилировал и понял причину странной загрузки процессора хотя бы в моменты, когда сортировка параллелится:
причина в том, что подмассивы разного размера и подмассив в потоке может сортироваться быстрее. Пока не понял, почему на 50% грузится второе ядро при однопоточной сортировке.
Один из основных вопросов, который меня волнует: как между процессами синхронизировать информацию о индексах новых подмассивов?
причина в том, что подмассивы разного размера и подмассив в потоке может сортироваться быстрее. Пока не понял, почему на 50% грузится второе ядро при однопоточной сортировке.
Один из основных вопросов, который меня волнует: как между процессами синхронизировать информацию о индексах новых подмассивов?
Всё наконец-то заработало. Жаль, что не 2^n потоков, не на Qt и не шаблонная, но меня уже надоело почти месяц ломать голову над этой задачей.
Теперь код для будущих поколений:
быстрая сортировка с++ qsort рспараллелить скачать без смс бесплатно
Теперь код для будущих поколений:
быстрая сортировка с++ qsort рспараллелить скачать без смс бесплатно
Код:
#define quint64 unsigned long
#define quint32 unsigned int
class _Sort
{
struct sortParams
{
std::vector<int>& buff;
quint64 l;
quint64 r;
sortParams(std::vector<int>& Buff, quint64 L, quint64 R): buff(Buff),l(L),r(R) {}
};
static DWORD WINAPI sortLocal4Threads(LPVOID P)
{
sortParams* p = static_cast<sortParams*>(P);
_Sort::qSortOneThread(p->buff,p->l,p->r);
return 0;
}
public:
static void qSortOneThread(std::vector<int>& Buff, quint64 l, quint64 r)
{
quint64 i=l;
quint64 j=r;
int x=Buff[(l+r)/2];
do
{
while(Buff<x) ++i;
while(Buff[j]>x) --j;
if(i<=j)
{
std::swap(Buff,Buff[j]);
i++;
j--;
}
}
while(i<=j);
if(l<j)
qSortOneThread(Buff,l,j);
if(i<r)
qSortOneThread(Buff,i,r);
}
static int qSort(std::vector<int>& Buff, size_t Size, quint32 ThreadCount)
{
quint64 i=0;
quint64 j=Size-1;
nth_element(Buff.begin(), Buff.begin()+((i+j)/2),Buff.end());
HANDLE hThread;
sortParams param(Buff,0,((i+j)/2)-1);
DWORD idThread;
hThread = CreateThread(NULL,0,_Sort::sortLocal4Threads,¶m,0,&idThread);
if (hThread == NULL)
{
std::cout << "Error while thread creation with code " << GetLastError()<<std::endl;
return 1;
}
qSortOneThread(Buff,((i+j)/2)+1,Size-1);
WaitForSingleObject(hThread,INFINITE);
return 0;
}
};
#define quint32 unsigned int
class _Sort
{
struct sortParams
{
std::vector<int>& buff;
quint64 l;
quint64 r;
sortParams(std::vector<int>& Buff, quint64 L, quint64 R): buff(Buff),l(L),r(R) {}
};
static DWORD WINAPI sortLocal4Threads(LPVOID P)
{
sortParams* p = static_cast<sortParams*>(P);
_Sort::qSortOneThread(p->buff,p->l,p->r);
return 0;
}
public:
static void qSortOneThread(std::vector<int>& Buff, quint64 l, quint64 r)
{
quint64 i=l;
quint64 j=r;
int x=Buff[(l+r)/2];
do
{
while(Buff<x) ++i;
while(Buff[j]>x) --j;
if(i<=j)
{
std::swap(Buff,Buff[j]);
i++;
j--;
}
}
while(i<=j);
if(l<j)
qSortOneThread(Buff,l,j);
if(i<r)
qSortOneThread(Buff,i,r);
}
static int qSort(std::vector<int>& Buff, size_t Size, quint32 ThreadCount)
{
quint64 i=0;
quint64 j=Size-1;
nth_element(Buff.begin(), Buff.begin()+((i+j)/2),Buff.end());
HANDLE hThread;
sortParams param(Buff,0,((i+j)/2)-1);
DWORD idThread;
hThread = CreateThread(NULL,0,_Sort::sortLocal4Threads,¶m,0,&idThread);
if (hThread == NULL)
{
std::cout << "Error while thread creation with code " << GetLastError()<<std::endl;
return 1;
}
qSortOneThread(Buff,((i+j)/2)+1,Size-1);
WaitForSingleObject(hThread,INFINITE);
return 0;
}
};