
Скоращение неиндексированных чтений
Доброго времени суток!
В БД новичёк. Возникла проблема при оптимизации запроса:

На изображении приведён анализ производительности. Очевидно что нужно сократить количество неиндексированных чтений, из таблиц user_track_rate и tracks.
Стандартный план предлагаемый СУБД Firebird:
Попытался сделать индексы таблицы для полей release_id и track_id из таблицы tracks, для поля user_id таблицы user_track_rate, но никаких изменений в плане не произошло, пытался прописать план вручную в запросе, он просто не скомпилировался. Может быть есть какие-то более мощные методы оптимизации?
В БД новичёк. Возникла проблема при оптимизации запроса:
Код:
SELECT tracks.track_id, COUNT(user_track_rate.user_id) FROM tracks, user_track_rate
WHERE (tracks.release_id IN (SELECT release_id FROM releases WHERE release_name LIKE 'W%'))
AND (user_track_rate.track_id IN (SELECT track_id FROM tracks WHERE release_id IN
(SELECT release_id FROM releases WHERE release_name LIKE 'W%')))
GROUP BY tracks.track_id
WHERE (tracks.release_id IN (SELECT release_id FROM releases WHERE release_name LIKE 'W%'))
AND (user_track_rate.track_id IN (SELECT track_id FROM tracks WHERE release_id IN
(SELECT release_id FROM releases WHERE release_name LIKE 'W%')))
GROUP BY tracks.track_id
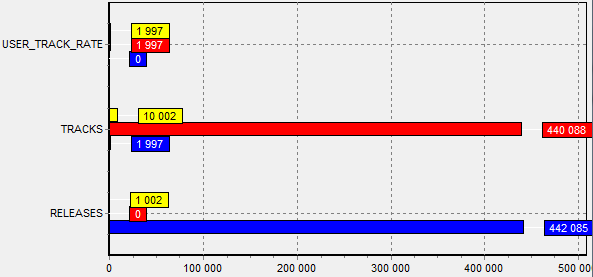
На изображении приведён анализ производительности. Очевидно что нужно сократить количество неиндексированных чтений, из таблиц user_track_rate и tracks.
Стандартный план предлагаемый СУБД Firebird:
Код:
PLAN (RELEASES INDEX (RDB$PRIMARY13))
PLAN (RELEASES INDEX (RDB$PRIMARY13))
PLAN (TRACKS INDEX (RDB$PRIMARY16))
PLAN SORT (JOIN (USER_TRACK_RATE NATURAL, TRACKS NATURAL))
PLAN (RELEASES INDEX (RDB$PRIMARY13))
PLAN (TRACKS INDEX (RDB$PRIMARY16))
PLAN SORT (JOIN (USER_TRACK_RATE NATURAL, TRACKS NATURAL))
Я конечно в firebird не силен. Но что-то я не вижу у вас условий соединения, так и задумывалось?
У вас есть два множества:
1) все строки из таблицы tracks у которых есть релизы с именем начинающимся с W.
2) все строки из таблицы user_track_rate, у которых есть треки, у которых есть релизы с таким именем.
То что вы написали, выдаст вам декартово произведение. этих двух множеств. Допустим у вас 100 трэков с буквы W, по каждому треку у вас 10 отзывов, т.е. всего 1000 отзывов для буквы W. В таком случае, то что вы написали, должно выдать вам 100 000 записей.
Может быть все-таки есть условие соединения, чтобы получить 1000 записей вместо 100 000?
Что-нить вроде: from tracks t join user_track_rate utr on t.track_id=utr.track_id
У вас есть два множества:
1) все строки из таблицы tracks у которых есть релизы с именем начинающимся с W.
2) все строки из таблицы user_track_rate, у которых есть треки, у которых есть релизы с таким именем.
То что вы написали, выдаст вам декартово произведение. этих двух множеств. Допустим у вас 100 трэков с буквы W, по каждому треку у вас 10 отзывов, т.е. всего 1000 отзывов для буквы W. В таком случае, то что вы написали, должно выдать вам 100 000 записей.
Может быть все-таки есть условие соединения, чтобы получить 1000 записей вместо 100 000?
Что-нить вроде: from tracks t join user_track_rate utr on t.track_id=utr.track_id